Here's a trade secret: Software Engineering is just a fancy term for data processing. Every digital product, like an application or a website, takes some data and transforms it into a different format.
Your digital product is no different: you collect and store the data provided by your customers or the internal team, and you generate web pages, emails, reports, notifications, and other result formats. One of the biggest challenges is making the data model that describes, collects, and enables processing the data powering your company.
Let's start with absolute basics: what is the primary function? Think about the purpose of your product: what is the most critical function that it provides? You can consider different classes of products:
- Data collection: your product collects and stores data provided by other systems or its users; there's not much processing involved if none. A typical product of this class might be a documentation system, blog engine, intranet application, and information-heavy system.
- Data processing: your product doesn't collect or store data, as its primary function is to process the data and send it to another system. A typical product of this class might be a data pipeline system for analytics, high-performance statistical system, or a communication system.
- Informational purpose: your product will both collect, store, and process the provided information, coming from multiple sources. Online stores, project management, task trackers, HR systems, Business Intelligence systems are the ideal products belonging to this class.
Why do we separate digital products into categories like these? Each class comes with a set of requirements, benefits, and risks to consider. For example, data collection products allow lots of freedom in the data model design because they contain mostly static content that doesn't change rapidly. Data processing products, on the other hand, require a minimalistic approach to the data model, as every bit of information affects the performance of the final product.
The second aspect of the data model to consider is what is the kind of data? Think about the information collected and processed by your product: does it fit into a specific structure? Answer to this question determines what kind of database and storage systems your product requires:
- Relational data can be organized in a collection of explicit tables containing strictly defined row structure made with columns. Each record (row in a table) contains the full amount of information alongside its identifier, including columns containing identifiers of its relation-based records. A store catalog is an ideal example: each product category has a clearly defined amount of information, and each product belongs to one or more categories.
- Non-relational data can be organized into collections or loosely-defined objects. Each object contains a custom amount of information organized in a dictionary (key-value) structure; values can be anything from a simple data, arrays of information, to complex nested structures of objects. This approach allows ultimate freedom in data model design because each object contains its data and all other information needed to process it. A task in a project management software is an ideal example: each task shares a bit of structure (like name and description) but can contain its custom data like checklists, comments, attachments.
- Key-value data is a special case of non-relational data worth mentioning. It organizes the information into a dictionary structure: each key has assigned value.
- Graph data is a highly specialized type of data describing objects and relations between them in the form of a graph. Social networks, recommendation engines, and Business Intelligence are ideal examples of graph data: they describe relations between objects in ways impossible or difficult for other types of data.
Let's catch a breath! If you feel dizzy and overwhelmed, don't worry: most of the B2C products are informational systems powered by relational data.
Even the Cubitoo Blog: it consists of a few article categories, many article tags, and of course, articles themselves. These three tables create the majority of the data stored and processed that we transform into the website you're reading now!
Here is a simplified data model of the Cubitoo Blog, using our simplified hand-written notation:
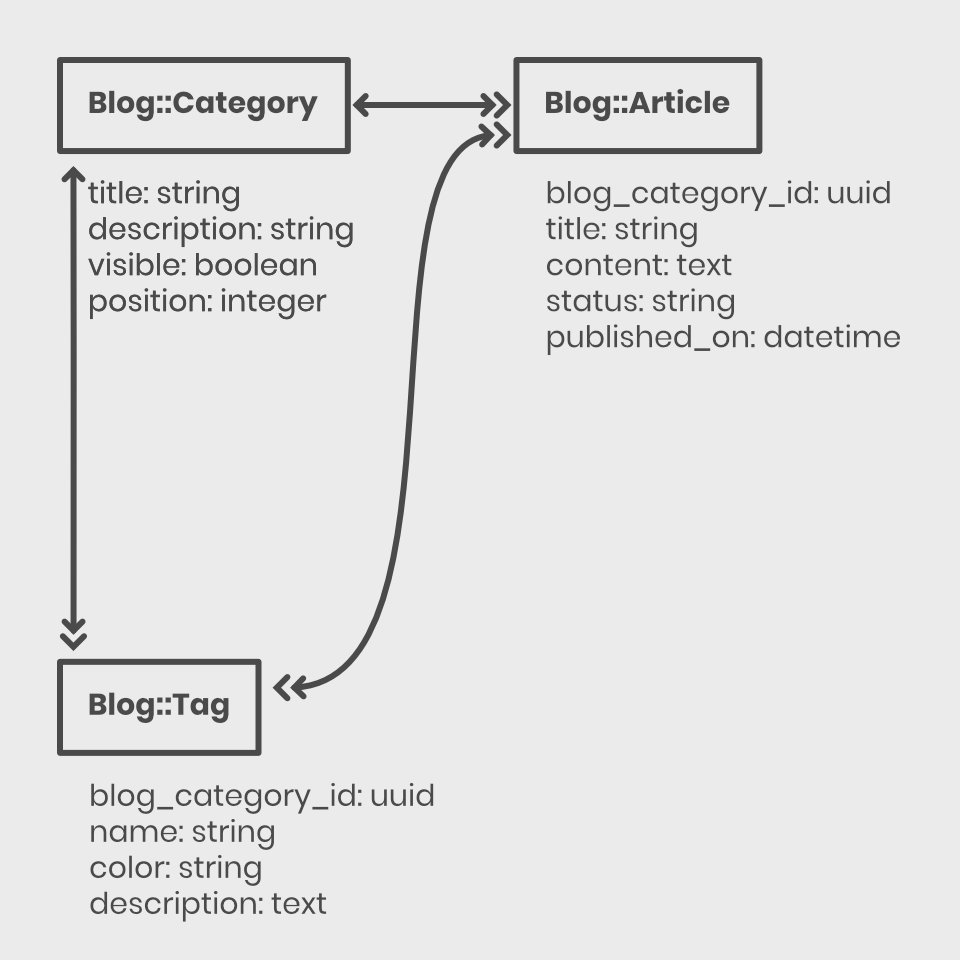
What is interesting about the data model is the use of relations between different tables to describe the blog structure: categories have many (↠) articles and analogically articles belong to (->) a category. Additionally, articles have and belong to many (↞↠) tags, enabling very flexible classification of content: an article belongs either to the Engineering or the Design category, but an article from either category can have the same tag assigned!
As your product grows and becomes more complicated, the data model evolves too. Having an overview of the complete structure prevents duplication and over-engineering, removes unnecessary complexity.
Using the simplified hand-written notation is a fun way to use pen and paper to design the data model of your product. It doesn't require the use of specialized software and allows small corrections and annotations.
Data model design makes the foundation of any digital product, and even if you don't feel comfortable betting technical about it, understanding the structure of your product's data has many benefits.
Cubitoo offers personalized coaching for startups and entrepreneurs, focusing on all aspects of lean and efficient product building, effective communication, and management. We will help you to build your own company. Learn more about coaching